📚 파이썬 프로그램, 자꾸만 꺼지는 미스터리 해결기: Buyma 데이터 수집기 안정화 대작전
💡 상황 해독
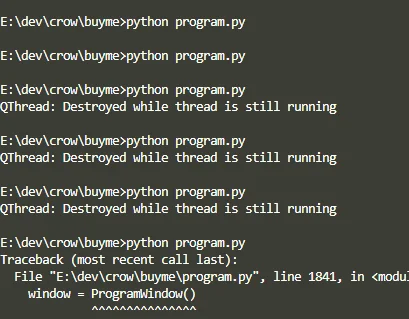
- 현재 상태: 열심히 만들던 Buyma 상품 정보 수집 프로그램이 중요한 작업(예: 수집한 데이터를 엑셀 파일로 만들거나, 많은 데이터를 불러올 때)만 하면 자꾸 힘없이 픽 꺼져버리는 상황입니다. 마치 중요한 발표를 앞두고 갑자기 컴퓨터가 먹통 되는 것처럼 답답한 상태였죠.
- 핵심 쟁점:
- 수집한 상품 정보와 어제 정보를 비교해 엑셀 보고서를 만드는 세 번째 단계(스크립트 3)에서 프로그램이 종종 멈춤.
- 상품 목록을 웹에서 가져오는 첫 번째 단계(스크립트 1)에서 인터넷 연결이 잠깐 불안정하면, 다시 시도하지 않고 바로 작업을 포기해버림.
- 특히 용량이 큰 데이터 파일(JSON 형식)을 한꺼번에 읽고 처리하려고 할 때 프로그램이 매우 힘겨워함.
- 예상 vs 현실:
- 예상: "버튼 한 번만 누르면 최신 상품 정보가 쫙 수집되고, 보기 좋게 정리된 엑셀 파일까지 자동으로 짠! 하고 만들어지겠지!"
- 현실: 실제로는 데이터 수집 중간이나 엑셀 생성 중에 프로그램이 예고 없이 종료되고, "도대체 어디가 문제야?" 하며 원인을 찾느라 많은 시간을 보냈습니다.
- 영향 범위: 프로그램이 자꾸 멈추니 원하는 시간 안에 데이터 수집을 끝내기 어렵고, 이는 곧 분석 작업 지연으로 이어졌습니다. 밤새도록 프로그램을 돌려놓고 아침에 확인했을 때 멈춰 있으면, 그 허탈감은 이루 말할 수 없었죠.
🔍 원인 투시
- 근본 원인: 프로그램이 한 번에 너무 많은 정보(데이터)를 기억하고 처리하려고 해서 컴퓨터의 작업 공간(메모리)이 부족해졌기 때문입니다. 마치 책상 위에 너무 많은 책을 한꺼번에 올려놓고 작업하려니 책상이 무너지는 것과 비슷합니다. 특히, 용량이 큰 JSON 파일을 기존 방식으로 다룰 때 이 문제가 두드러졌습니다.
- 연결 고리:
- 스크립트 3 (엑셀 보고서 생성 문제): 기존에는 오늘 수집한 상품 데이터와 어제 수집한 상품 데이터를 파일에서 읽어와 컴퓨터 메모리에 통째로 올린 후, 하나하나 비교하며 엑셀에 들어갈 내용을 만들었습니다. 데이터 양이 많아지니 컴퓨터가 감당할 수 있는 메모리 한계를 초과했고, 결국 프로그램이 강제 종료된 것입니다.
- 스크립트 1 (페이지 요청 재시도 부재 문제): Buyma 웹사이트에서 상품 목록 페이지 정보를 가져올 때, 인터넷 연결이 순간적으로 끊기거나 웹사이트 응답이 잠깐 없으면, 프로그램은 "어? 안 되네?" 하고 바로 다음 작업으로 넘어가거나 오류로 처리했습니다. 한두 번 더 시도해보면 성공할 수도 있었는데, 그런 끈기가 부족했던 것이죠.
- 일상 비유:
- 메모리 초과 문제 (스크립트 3):
- 도서관에서 책 찾기: 수천 권의 책(상품 데이터) 목록이 적힌 두루마리 종이 두 개(오늘/어제 데이터 파일)를 한 번에 펼쳐놓고, 두 목록을 비교하며 특정 책(상품)의 정보 변화를 찾는 것과 같습니다. 책상이 좁다면(메모리가 부족하면) 두루마리가 뒤엉키고 결국 작업을 제대로 할 수 없게 됩니다.
- 요리 레시피: 수백 페이지짜리 요리책 두 권(데이터 파일)을 통째로 외워서(메모리에 로드) 동시에 두 가지 요리(오늘/어제 데이터 비교)를 하려는 것과 같습니다. 당연히 머리가 복잡해지고(메모리 부족) 요리를 망치기(프로그램 종료) 쉽습니다.
- Pandas DataFrame 도입 후 (스크립트 3 개선):
- 디지털 도서 관리 시스템: 이전의 두루마리 대신, 잘 정리된 디지털 도서 관리 시스템(Pandas DataFrame)에 책 목록을 입력하는 것과 같습니다. 시스템은 각 책에 고유번호(상품 ID)를 부여하고, 특정 조건(예: '어제는 있었는데 오늘 없는 책')에 맞는 책을 빠르고 효율적으로 찾아줍니다. 필요한 정보만 쏙쏙 뽑아 쓰니 훨씬 가볍습니다.
- 재시도 로직 부재 (스크립트 1):
- 인기 맛집 전화 예약: 인기 맛집에 전화했는데 첫 번째 시도에서 통화 중이라고 바로 포기하고 다른 식당을 알아보는 것과 같습니다. 몇 분 뒤에 다시 걸어보면 예약에 성공할 수도 있는데 말이죠.
- 숨겨진 요소:
- "소리 없는 아우성": 명확한 에러 메시지를 보여주며 종료되는 경우보다, 아무런 메시지 없이 프로그램이 그냥 꺼져버리는 현상이 원인 파악을 더 어렵게 만듭니다.
- 근본적인 해결책의 중요성: 단순히 코드 몇 줄을 추가하거나 임시방편으로 문제를 덮는 것보다, 데이터 처리 방식 자체를 더 효율적인 것으로(예: JSON 직접 처리 → Pandas DataFrame 사용) 바꾸는 것이 장기적으로 더 나은 해결책이 될 수 있습니다.
- 만병통치약은 없다:
gc.collect()처럼 메모리를 수동으로 정리하는 코드가 항상 좋은 것은 아닙니다. 잘못 사용하면 오히려 프로그램 성능을 떨어뜨리거나, 문제 해결에 큰 도움이 되지 않을 수도 있습니다.
🛠️ 해결 설계도
- 스크립트 3 엑셀 생성 중단 문제 해결: "무거운 짐, 스마트하게 나눠 들기" (Pandas로 데이터 다루기)
- 핵심 행동: 용량이 큰 JSON 데이터 파일을 통째로 메모리에 올리는 대신, 데이터 분석 전문 도구인 'Pandas' 라이브러리를 사용하여 데이터를 훨씬 효율적으로 읽고, 처리하고, 엑셀 파일로 저장합니다.
- 실행 가이드:
- 기존에
json.load()함수로 JSON 파일을 읽던 부분을pd.read_json()함수로 변경하여, 데이터를 Pandas의 DataFrame이라는 특별한 표 형태로 바로 불러옵니다. - 오늘 데이터와 어제 데이터를 비교하고, 증가량을 계산하는 등의 작업을 DataFrame이 제공하는 편리한 기능들(예:
merge, 산술 연산)을 사용하여 수행합니다. - 최종적으로 만들어진 DataFrame을
to_excel()함수를 사용하여 엑셀 파일로 간단하게 저장합니다.
- 성공 지표: 이전에는 수천 건의 데이터를 처리할 때 멈추던 프로그램이, 이제는 수만 건 이상의 데이터도 안정적으로 처리하며 엑셀 파일을 빠르게 생성합니다. 메모리 사용량도 눈에 띄게 줄어듭니다.
- 예시/코드:
// 변경 전 (Script3Worker의 process_seller 메소드 대략적인 로직)
// with open(today_file_path, 'r') as f:
// products_today_list = json.load(f)
// with open(yesterday_file_path, 'r') as f:
// products_yesterday_list = json.load(f)
//
// combined_data = []
// for today_item in products_today_list:
// # 어제 데이터에서 해당 상품 찾아 비교하는 복잡한 반복문 로직...
// # 엑세스 수 직접 파싱하고 계산...
// combined_data.append(...)
// # 이 데이터를 기반으로 엑셀 생성...
// 변경 후 (Script3Worker의 process_seller 메소드 핵심 로직)
df_today = pd.read_json(today_file_path, orient='records')
# '엑세스수' 컬럼을 숫자로 변환하여 '오늘 엑세스수' 컬럼 생성
df_today[self.COL_ACCESS_COUNT_TODAY] = df_today['엑세스수'].apply(self.parse_access_count)
if yesterday_file_path:
df_yesterday = pd.read_json(yesterday_file_path, orient='records')
df_yesterday[self.COL_ACCESS_COUNT_YESTERDAY] = df_yesterday['엑세스수'].apply(self.parse_access_count)
# '상품_ID'를 기준으로 오늘 데이터와 어제 데이터를 병합 (SQL의 JOIN과 유사)
df_final_report = pd.merge(df_today, df_yesterday[[self.COL_PRODUCT_ID, self.COL_ACCESS_COUNT_YESTERDAY]],
on=self.COL_PRODUCT_ID, how='left')
else:
df_final_report = df_today
df_final_report[self.COL_ACCESS_COUNT_YESTERDAY] = 0 # 어제 데이터 없으면 0으로 채움
# NaN 값을 0으로 채우고, 증가량 계산
df_final_report[self.COL_ACCESS_COUNT_TODAY] = df_final_report[self.COL_ACCESS_COUNT_TODAY].fillna(0).astype(int)
df_final_report[self.COL_ACCESS_COUNT_YESTERDAY] = df_final_report[self.COL_ACCESS_COUNT_YESTERDAY].fillna(0).astype(int)
df_final_report[self.COL_ACCESS_INCREASE] = df_final_report[self.COL_ACCESS_COUNT_TODAY] - df_final_report[self.COL_ACCESS_COUNT_YESTERDAY]
# 썸네일 URL의 NaN 값을 빈 문자열로 채움
if self.COL_THUMBNAIL_URL in df_final_report.columns:
df_final_report[self.COL_THUMBNAIL_URL] = df_final_report[self.COL_THUMBNAIL_URL].fillna('')
// 최종 결과(df_final_report)를 엑셀로 저장
// df_to_save.to_excel(output_excel_filename, index=False, engine='openpyxl')
// 핵심 변화 설명
// 이전에는 파이썬 기본 리스트와 딕셔너리를 사용하여 모든 데이터를 수동으로 반복하며 비교하고 조합했습니다.
// 이는 데이터가 커질수록 매우 비효율적이고 메모리를 많이 차지합니다.
// 변경 후에는 Pandas의 DataFrame을 사용하여 마치 데이터베이스를 다루듯,
// 또는 엑셀의 고급 기능을 사용하듯 데이터를 훨씬 간결하고 빠르게 처리합니다.
// 'merge' 한 줄로 복잡한 비교 로직이 해결되고, 산술 연산도 컬럼 단위로 쉽게 적용됩니다.
// 결과적으로 메모리 사용량이 크게 줄고, 코드도 훨씬 깔끔해졌습니다.
- 주의사항: Pandas 라이브러리 사용법에 대한 기본적인 이해가 필요합니다. DataFrame의 컬럼 이름이나 데이터 타입(숫자, 문자열 등)을 정확히 알고 다뤄야 하며, 데이터 병합 시 기준이 되는 컬럼(예:
상품_ID)이 양쪽 DataFrame에 모두 존재해야 합니다. 또한,fillna('')처럼 데이터가 없는 경우(NaN) 어떻게 처리할지 명확히 정의해주는 것이 좋습니다.
- 스크립트 1 페이지 요청 실패 시 자동 재시도: "칠전팔기 정신 탑재"
- 핵심 행동: Buyma 웹사이트에서 상품 목록이 있는 페이지를 불러올 때, 만약 한 번에 성공하지 못하면 포기하지 않고, 미리 정해둔 횟수만큼 자동으로 다시 시도하는 기능을 추가합니다.
- 실행 가이드:
Script1Worker의page_worker_s1함수 내에서 실제 웹페이지 내용을 가져오는 부분(self.get_page_html_async_s1)을for반복문으로 감쌉니다. 이 반복문은MAX_PAGE_FETCH_ATTEMPTS_S1(예: 3번) 만큼 실행됩니다.- 페이지 요청에 실패하면, 로그를 남기고
RETRY_DELAY_SECONDS_S1(예: 1초) 만큼 잠시 기다린 후 다음 시도를 진행합니다. - 만약 프록시 IP를 사용 중이라면, 다음 시도에서는 다른 프록시 IP를 사용하도록 합니다. (코드에서는
next(proxy_cycler)가 이 역할을 합니다) - 모든 재시도에도 불구하고 실패하면, 해당 페이지는 건너뛰고 다음 작업을 계속합니다.
- 성공 지표: 일시적인 네트워크 오류, 프록시 IP 차단, 웹사이트의 순간적인 반응 없음 등의 문제로 첫 번째 페이지 로딩에 실패하더라도, 프로그램이 바로 멈추거나 오류를 내뱉지 않습니다. 대신, 몇 번 더 끈기 있게 시도하여 결국 페이지 정보를 가져오거나, 정해진 시도 횟수를 다 소진한 후에야 해당 페이지 처리를 포기합니다. 이로써 전체 데이터 수집 성공률이 높아집니다.
- 예시/코드:
// 변경 전 (Script1Worker - page_worker_s1 대략적인 로직)
// html_text = await self.get_page_html_async_s1(session, page_url, seller_name, current_proxy_for_attempt)
// if not html_text:
// self.log_signal.emit(f" 페이지 내용 가져오기 실패. 건너뜁니다.")
// // 바로 실패 처리하고 다음으로 넘어감
// 변경 후 (Script1Worker - page_worker_s1 핵심 로직)
html_text = None # html_text 초기화
for attempt in range(MAX_PAGE_FETCH_ATTEMPTS_S1): # 최대 시도 횟수만큼 반복
if not self.is_running: # 작업 중단 요청 시 즉시 중단
break
current_proxy_for_attempt = next(proxy_cycler) if proxy_cycler else None
log_prefix = f"[S1 워커 {name}, 페이지 {page_num_to_process}, 시도 {attempt + 1}/{MAX_PAGE_FETCH_ATTEMPTS_S1}]"
# 실제 페이지 요청
html_text = await self.get_page_html_async_s1(session, page_url, seller_name, current_proxy_for_attempt)
if html_text: # 페이지 내용 가져오기 성공!
self.log_signal.emit(f" {log_prefix} 페이지 내용 가져오기 성공.")
break # 재시도 루프 탈출
else: # 실패 시
self.log_signal.emit(f" {log_prefix} 페이지 내용 가져오기 실패 (프록시: {current_proxy_for_attempt or '없음'}).")
if attempt < MAX_PAGE_FETCH_ATTEMPTS_S1 - 1 and self.is_running: # 마지막 시도가 아니고, 작업 중단 요청이 없다면
if proxy_cycler: # 프록시 사용 중이면 다음 프록시로 재시도
self.log_signal.emit(f" {RETRY_DELAY_SECONDS_S1}초 후 다른 프록시로 재시도합니다...")
else: # 프록시 미사용 중이면 같은 IP로 재시도
self.log_signal.emit(f" {RETRY_DELAY_SECONDS_S1}초 후 재시도합니다...")
await asyncio.sleep(RETRY_DELAY_SECONDS_S1) # 잠시 대기
elif not self.is_running:
self.log_signal.emit(f" 작업 중단으로 재시도를 중단합니다.")
break
if not html_text: # 모든 시도 후에도 html_text가 None이면 최종 실패
self.log_signal.emit(f" [S1 워커 {name}] {seller_name} / {page_num_to_process} 페이지 최종 실패. 건너뜁니다.")
# page_queue.task_done() 은 이미 try-except-finally 또는 async with semaphore 블록 종료 시 처리될 것임
# continue # 다음 페이지 처리를 위해 루프의 처음으로 (만약 이 코드가 while 루프의 일부라면)
// 핵심 변화 설명
// 이전에는 웹페이지 요청을 단 한 번만 시도하고, 실패하면 바로 다음으로 넘어갔습니다.
// 변경 후에는 for 반복문을 사용하여, 요청이 실패하더라도 정해진 횟수(MAX_PAGE_FETCH_ATTEMPTS_S1)만큼
// 일정 시간(RETRY_DELAY_SECONDS_S1) 간격을 두고 다시 시도합니다.
// 프록시를 사용한다면 매번 다른 프록시로 시도하여 성공 가능성을 높입니다.
// 이를 통해 프로그램이 일시적인 문제에 더 잘 대처하고, 데이터 수집의 안정성을 크게 향상시켰습니다.
- 주의사항: 재시도 횟수(
MAX_PAGE_FETCH_ATTEMPTS_S1)나 재시도 간 대기 시간(RETRY_DELAY_SECONDS_S1)을 너무 과도하게 설정하면, 특정 페이지에서 문제가 발생했을 때 프로그램이 오랫동안 멈춰있거나 상대방 웹사이트에 불필요한 부담을 줄 수 있습니다. 적절한 값을 설정하는 것이 중요합니다.
🧠 핵심 개념 해부
- Pandas DataFrame (데이터프레임): 당신의 데이터를 위한 똑똑한 슈퍼 정리함
- 5살에게 설명한다면: 레고 블록(데이터)이 엄청 많이 담긴 커다란 통(데이터 파일)이 있다고 상상해봐. 이 블록들을 색깔별, 모양별, 크기별로 칸칸이 아주 예쁘게 정리해주는 마법 같은 정리함이 바로 '데이터프레임'이야. 그래서 네가 "빨간색 네모 블록만 줘!" 하면 바로 착 꺼내줄 수 있고, "제일 큰 블록이 뭐야?" 하면 바로 알려줄 수 있어.
- 실생활 예시: 우리가 흔히 사용하는 엑셀(Excel) 스프레드시트와 매우 비슷하지만, 컴퓨터 프로그래밍으로 다루기 훨씬 편하고 훨씬 더 많은 양의 데이터를 훨씬 빠르게 처리할 수 있는 강력한 도구입니다. 예를 들어, 수백만 명의 고객 정보가 담긴 파일에서 특정 조건을 만족하는 고객만 순식간에 골라내거나, 각 상품의 월별 판매량을 자동으로 계산해서 표로 보여주는 작업을 할 수 있습니다. (이번 스크립트 3에서 JSON 데이터를 DataFrame으로 바꿔서 엑셀 만들 때 사용했죠.)
- 숨겨진 중요성: 단순히 데이터를 표 형태로 보여주는 것을 넘어서, 복잡한 데이터 분석, 불필요한 데이터 제거, 원하는 형태로 데이터 가공, 여러 데이터 합치기 등의 작업을 단 몇 줄의 코드로 매우 간편하게 처리할 수 있게 해줍니다. 특히 많은 양의 데이터를 다룰 때 메모리를 효율적으로 사용하도록 설계되어 있어 프로그램 성능 향상에 큰 도움을 줍니다.
- 오해와 진실:
- 오해: "엑셀이랑 그냥 비슷한 거 아니야? 엑셀 쓰면 되지."
- 진실: 엑셀과 보이는 것은 비슷할 수 있지만, Pandas는 프로그래머를 위한 도구로, 훨씬 더 복잡하고 큰 데이터를 다루며 자동화된 분석 작업을 수행하는 데 특화되어 있습니다. 엑셀이 할 수 없는 많은 고급 분석 기능을 제공합니다.
- 오해: "데이터 양이 적으면 굳이 Pandas까지 쓸 필요 없지 않나?"
- 진실: 데이터 양이 적더라도 Pandas를 사용하면 데이터를 다루는 코드가 훨씬 간결하고 표준화되어 다른 사람이 이해하기 쉬워집니다. 또한, 나중에 데이터 양이 늘어나더라도 코드 변경 없이 그대로 사용할 수 있는 장점이 있습니다.
- 비동기 처리 (Asynchronous Processing, Asyncio): 혼자서 여러 손님 동시에 상대하는 멀티태스킹 마법
- 5살에게 설명한다면: 네가 식당 주방장인데, 손님 한 명 주문받고 요리 다 만들어서 나갈 때까지 다른 손님 주문을 전혀 안 받는 게 아니라, 여러 손님 주문을 일단 다 받아놓고, 재료 준비되는 대로 여러 요리를 동시에 조금씩 만들어 나가는 것과 비슷해. 한 가지 일이 끝날 때까지 마냥 기다리지 않고, 다른 할 수 있는 일들을 중간중간 처리해서 전체적으로 일을 더 빨리 끝내는 방법이야.
- 실생활 예시: 여러 웹사이트에서 동시에 뉴스 기사를 스크래핑(수집)하는 작업을 상상해봅시다. 첫 번째 웹사이트에서 기사 내용을 다 가져올 때까지 멍하니 기다리는 것이 아니라, 여러 웹사이트에 동시에 "기사 내놔!" 하고 요청을 보내놓고, 각 웹사이트에서 응답이 오는 대로 차례차례 기사를 받아 처리하는 방식입니다. (우리 프로그램에서는 스크립트 1과 2에서 Buyma 웹사이트에 상품 정보나 엑세스 수를 요청할 때 이 방식을 사용합니다.)
- 숨겨진 중요성: 프로그램이 어떤 작업(특히 웹사이트 응답 기다리기, 파일 읽고 쓰기처럼 컴퓨터 외부 장치와 통신하는 작업, 이를 I/O 작업이라 합니다)을 요청하고 그 결과가 올 때까지 아무것도 못하고 멈춰있는 시간을 크게 줄여줍니다. 이 "기다리는 시간" 동안 다른 유용한 작업을 처리할 수 있게 만들어, 프로그램 전체의 실행 효율과 반응 속도를 극적으로 높여줍니다.
- 오해와 진실:
- 오해: "코드가 너무 복잡해지고 어려워지는 거 아니야?"
- 진실:
async와await같은 새로운 문법이 처음에는 낯설 수 있지만, 일단 익숙해지면 특정 작업들의 논리적인 흐름을 더 명확하게 표현할 수 있게 해줍니다. 오히려 잘만 활용하면 복잡한 동시성 문제를 더 쉽게 해결할 수 있습니다. - 오해: "비동기 처리를 쓰면 무조건 프로그램이 엄청 빨라지는 건가?"
- 진실: CPU 자체의 계산이 매우 많은 작업(예: 복잡한 수학 연산)에서는 큰 효과를 보기 어려울 수 있습니다. 하지만 우리 프로그램처럼 네트워크 요청을 보내고 응답을 기다리는 시간이 대부분인 I/O 바운드(I/O-bound) 작업에서는 마치 여러 작업을 동시에 처리하는 것처럼 보여 엄청난 성능 향상을 가져올 수 있습니다.
- JSON (제이슨, JavaScript Object Notation): 컴퓨터 세계의 공용어 쪽지
- 5살에게 설명한다면: 우리가 친구랑 말로 대화하거나 그림으로 편지를 주고받는 것처럼, 컴퓨터들도 서로 정보를 주고받을 때 사용하는 특별한 약속 같은 거야. "이름: 뽀로로", "나이: 5살", "좋아하는 것: [노래하기, 눈싸움]" 이런 식으로, 누가 봐도 쉽게 알아볼 수 있도록 깔끔하게 정리해서 정보를 적는 방법이지.
- 실생활 예시: 우리가 웹사이트에서 어떤 상품을 클릭하면, 그 상품의 이름, 가격, 설명 같은 정보들이 우리 눈에는 보이지 않지만 컴퓨터 내부에서는 이 JSON이라는 형식으로 웹서버와 우리 컴퓨터 사이에 오고 갑니다. 우리 프로그램에서도 Buyma 웹사이트에서 가져온 상품 정보들이 이 JSON 형태로 되어 있고, 수집한 데이터를 파일로 저장할 때도 이 형식을 사용했습니다.
- 숨겨진 중요성: 사람이 읽고 이해하기 쉬울 뿐만 아니라, 컴퓨터 프로그램이 분석하고 처리하기도 매우 쉽게 설계되어 있습니다. 특정 프로그래밍 언어(예: 파이썬, 자바스크립트, 자바 등)에 얽매이지 않고 대부분의 언어에서 쉽게 사용할 수 있어서, 서로 다른 시스템이나 프로그램 간에 데이터를 주고받는 표준 형식으로 널리 사용됩니다.
- 오해와 진실:
- 오해: "그냥 일반 텍스트 파일이랑 똑같은 거 아니야?"
- 진실: 텍스트를 기반으로 하지만, 중괄호
{}(객체), 대괄호[](배열), 그리고 "키(key): 값(value)" 쌍과 같은 정해진 구조와 규칙을 가지고 있어서 단순 텍스트 파일과는 다릅니다. - 오해: "이름에 자바스크립트가 들어가니 자바스크립트 전용인가?"
- 진실: 이름은 자바스크립트에서 유래했지만, 현재는 자바스크립트뿐만 아니라 파이썬을 포함한 거의 모든 프로그래밍 언어에서 매우 광범위하게 지원하고 사용하는 데이터 형식입니다.
- 디버깅 및 로깅 (Debugging & Logging): 프로그램 탐정의 수사 기법
- 5살에게 설명한다면: 네가 아끼는 로봇 장난감이 갑자기 움직이지 않을 때, "어디가 아픈 걸까? 배터리가 다 됐나? 아니면 팔이 빠졌나?" 하고 구석구석 살펴보는 것처럼, 프로그램이 왜 제대로 작동하지 않는지 원인을 찾아서 고치는 과정을 '디버깅'이라고 해. 그리고 '로깅'은 로봇이 "나 지금 팔을 움직이려고 해!", "앗! 다리에 힘이 안 들어가!" 하고 너에게 계속 말해주는 것과 같아. 프로그램이 뭘 하고 있는지, 어디서 문제가 생겼는지 알려주는 중요한 단서들이지.
- 실생활 예시: 코드를 실행하다가 예상치 못한 결과가 나올 때,
print()함수를 사용해서 중간중간 변수 값이 어떻게 변하는지 찍어보는 것. 또는try-except구문을 사용해서 오류가 발생했을 때 어떤 종류의 오류인지, 어느 부분에서 발생했는지 메시지를 출력하도록 하는 것. 우리 프로그램 문제 해결 과정에서도 "스크립트 3에서 특정 아이템 처리 중 멈춤" 같은 로그를 통해 문제의 실마리를 잡을 수 있었습니다. - 숨겨진 중요성: 프로그램이 복잡해질수록, 또는 눈에 보이지 않는 서버에서 실행될수록, 오류가 발생했을 때 그 지점과 원인을 정확하게 파악하는 것은 매우 어렵습니다. 체계적인 디버깅 방법과 상세한 로깅 습관은 문제 해결 시간을 극적으로 단축시켜주고, 프로그램의 유지보수를 훨씬 쉽게 만들어줍니다.
- 오해와 진실:
- 오해: "진짜 고수 프로그래머들은 디버깅 같은 거 안 하고 한 번에 완벽한 코드를 짜지 않나?"
- 진실: 아무리 숙련된 개발자라도 처음부터 완벽한 코드를 작성하기는 어렵습니다. 오히려 뛰어난 개발자일수록 체계적인 디버깅 기술과 효과적인 로깅 전략의 중요성을 더 잘 알고 적극적으로 활용합니다.
- 오해: "간단한 오류는 그냥
print()몇 번 찍어보면 다 잡히지 않나?" - 진실: 간단한 경우에는
print()가 유용할 수 있지만, 복잡한 조건 분기, 여러 모듈이 얽힌 경우, 특히 비동기 프로그래밍 환경에서는logging모듈과 같은 전문 로깅 도구나 통합 개발 환경(IDE)에서 제공하는 디버거를 사용하는 것이 훨씬 효율적이고 강력합니다.
🔮 미래 전략 및 지혜
- 예방 전략: (똑같은 실수를 반복하지 않기 위한 구체적인 방법 3가지)
- "큰 데이터는 처음부터 Pandas로!": 앞으로 용량이 큰 JSON 파일이나 CSV 파일 같은 데이터를 다룰 때는, 처음부터 Pandas DataFrame으로 불러와서 처리하는 것을 습관화합니다. 이렇게 하면 메모리 문제를 미리 예방하고, 데이터 가공도 훨씬 수월해집니다. (마치 무거운 짐은 손으로 들려 하지 말고 처음부터 바퀴 달린 카트에 싣는 것처럼!)
- "외부 연결은 항상 의심하고 대비하라!": 웹사이트에서 정보를 가져오거나, 파일을 읽고 쓰는 것처럼 프로그램 외부의 자원과 통신할 때는 항상 문제가 생길 수 있다고 가정합니다. 그래서 반드시 ①타임아웃(너무 오래 기다리지 않도록 시간제한 설정), ②재시도 로직(실패 시 몇 번 더 시도), ③예외 처리(오류 발생 시 프로그램이 멈추지 않고 적절히 대응)를 꼼꼼하게 구현합니다. (마치 낯선 문을 열기 전에, 문이 잠겨있을 수도 있고, 갑자기 뭔가 튀어나올 수도 있다고 대비하는 것처럼!)
- "조금씩 만들고, 자주 테스트하라!": 한 번에 너무 많은 기능을 왕창 만들려고 하지 말고, 작은 기능 단위로 나누어 개발하고, 각 기능이 완성될 때마다 충분히 테스트하여 안정성을 확보해나갑니다. 이렇게 하면 나중에 큰 문제가 터지는 것을 막고, 문제가 생겨도 원인을 찾기 훨씬 쉽습니다. (마치 높은 레고 성을 쌓을 때, 한 층 한 층 쌓을 때마다 제대로 붙었는지, 흔들리지는 않는지 확인하며 올라가는 것처럼!)
- 장기적 고려사항: (이번 경험에서 얻을 수 있는 단순한 기술 이상의 교훈)
- 이번 문제 해결 과정을 통해, 단순히 "코드를 짜서 돌아가게 만드는 것"을 넘어, "프로그램의 성능(메모리 사용량, 실행 속도)과 안정성(오류에 대한 대처 능력)까지 깊이 고민해야 한다"는 중요한 교훈을 얻었습니다. "어떻게든 되게 만들자"가 아니라, "오래도록 잘, 그리고 효율적으로 돌아가게 만들자"는 자세가 중요하다는 것을 깨달았습니다. 또한, 문제가 발생했을 때 포기하지 않고, 체계적으로 원인을 분석하고 다양한 해결책을 시도하는 끈기와 문제 해결 능력이 개발자에게 얼마나 중요한지도 다시 한번 느꼈습니다.
- 전문가 사고방식: (만약 이 분야의 숙련된 전문가였다면, 이 상황을 어떻게 생각하고 접근했을까?)
- "음, 프로그램이 특정 지점에서 자꾸 멈춘다고? 가장 먼저 의심해볼 것은 메모리 관련 문제나 무한 루프, 혹은 외부 I/O 대기 시간 문제군. 로그를 좀 더 자세히 심어서 어느 부분에서 정확히 얼마나 시간을 소요하는지, 혹은 어떤 데이터 처리 직전에 멈추는지부터 파악해야겠어."
- "데이터 크기가 크다면, 전통적인 방식의 파일 로딩과 순차 처리는 분명 한계가 있을 거야. Pandas 같은 메모리 효율적인 라이브러리 사용을 고려하거나, 데이터를 한 번에 다 올리지 않고 필요한 만큼씩 나눠서 처리(스트리밍 또는 청크 방식)하는 방법을 생각해봐야지."
- "네트워크 요청이 실패하는 건 다반사니까, 재시도 로직은 기본으로 넣어야 하고, 재시도 간격은 너무 짧지도 길지도 않게, 그리고 상대 서버에 부담을 주지 않는 선에서 조절해야겠군. 익스포넨셜 백오프(Exponential Backoff: 재시도할수록 대기 시간을 점차 늘리는 방식) 전략도 고려해볼 만해."
- "단순히 문제를 해결하는 데 그치지 않고, 이 문제가 왜 발생했는지 근본적인 원인을 이해하고, 앞으로 비슷한 유형의 문제가 재발하지 않도록 시스템적으로 어떻게 개선할 수 있을지 고민해야 진짜 해결이지."
- 학습 로드맵: (이 주제(파이썬을 이용한 데이터 수집 및 처리, 프로그램 안정화)를 더 깊이 이해하기 위한 단계별 학습 경로)
- 파이썬 중급 문법 및 표준 라이브러리 복습 (1~2주):
- 이터레이터와 제너레이터 (메모리 효율적 데이터 처리)
collections모듈 (효율적인 자료구조 활용)datetime모듈 (시간/날짜 처리 마스터)- 정규 표현식 (
re모듈) (문자열 패턴 매칭)
- 데이터 처리의 핵심, Pandas 마스터하기 (2~4주):
- DataFrame 및 Series 완벽 이해 (생성, 선택, 필터링, 수정)
- 다양한 데이터 소스(CSV, JSON, Excel, DB) 읽고 쓰기
- 그룹화(Groupby), 병합(Merge, Join, Concat), 피벗 테이블
- 결측치(Missing Data) 처리, 데이터 타입 변환, 문자열 처리
- 시계열 데이터(Time Series) 분석 기초
- 추천 자료: "Python for Data Analysis" (Pandas 창시자 Wes McKinney 저)
- 효율적인 비동기 프로그래밍 (Asyncio & Aiohttp) 정복 (2~3주):
- 이벤트 루프, 코루틴,
async/await문법 심층 이해 aiohttp를 이용한 비동기 HTTP 요청 (세션 관리, 타임아웃, 에러 처리)- 동시성 제어 (
asyncio.Semaphore,asyncio.Queue) - 비동기 작업 취소 및 예외 처리
- 추천 자료: 파이썬 공식 문서 Asyncio 파트, "Fluent Python" (Luciano Ramalho 저) 중 관련 챕터
- 견고한 프로그램을 위한 로깅 및 디버깅 전략 (1~2주):
- 파이썬
logging모듈 고급 활용 (포맷터, 핸들러, 필터, 설정 파일 사용) - 구조화된 로깅 (JSON 로그 등)
- 통합 개발 환경(IDE)의 디버거 사용법 숙달 (VSCode, PyCharm 등)
pdb(Python Debugger) 사용법
- PyQt5 애플리케이션 구조 및 성능 최적화 (2~3주, GUI 관련):
- PyQt5의 스레딩 이해 (QThread 심화, GUI와 워커 스레드 분리)
- 사용자 정의 시그널/슬롯 고급 활용 (데이터 전달, 스레드 간 통신)
- GUI 업데이트 최적화 (불필요한 업데이트 줄이기)
- 프로파일링 도구를 이용한 GUI 애플리케이션 병목 지점 찾기
🌟 실전 적용 청사진
- 즉시 적용: (지금 당장 코드에 반영해볼 수 있는 3가지 작은 액션)
- 가장 큰 JSON 파일 Pandas로 읽기: 현재 프로젝트에서
json.load로 읽고 있는 파일 중 가장 크거나 자주 문제를 일으켰던 파일 하나를 골라pd.read_json()으로 바꿔보고, 간단한 처리(예: 특정 컬럼만 선택, 특정 조건으로 필터링)를 Pandas로 시도해보세요. - 가장 불안정한 웹 요청에 재시도 추가: 스크립트 1 또는 2에서 가장 자주 실패하거나 중요하다고 생각되는 웹 요청(예:
get_page_html_async_s1또는get_access_count_async) 부분에,for attempt in range(2):와 같이 간단하게 2번 정도만 재시도하는 로직을 추가하고,await asyncio.sleep(1)로 1초 정도 대기하는 코드를 넣어보세요. - 핵심 함수 입출력 로깅:
Script3Worker의process_seller함수 시작 시 "처리 시작: [판매자명]" 로그를, 종료 시 "처리 완료: [판매자명], 결과 건수: [숫자]" 로그를 추가하고,run메소드에서도 주요 분기점마다 현재 상태나 변수 값을 로그로 남겨보세요.
- 중기 프로젝트: (1주일 ~ 4주일 정도 시간을 들여 시도해볼 만한 프로젝트)
- "우리 집 데이터, SQLite 데이터베이스로 이사시키기":
- 현재 각 스크립트 단계마다 JSON 파일로 중간 데이터를 저장하고 다음 단계에서 다시 읽는 방식을 사용하고 있습니다. 이를 개선하여, 스크립트 1에서 수집한 상품 기본 정보, 스크립트 2에서 수집한 엑세스 수 정보 등을 SQLite 같은 가벼운 로컬 데이터베이스에 차곡차곡 저장하도록 변경해보세요. 스크립트 3에서는 이 데이터베이스에서 필요한 정보를 SQL 쿼리(또는 Pandas의
read_sql기능)로 가져와서 보고서를 생성합니다. - 기대 효과: 파일 관리가 훨씬 쉬워지고, 데이터 무결성을 지키기 용이해집니다. 특정 판매자나 특정 날짜의 데이터만 골라보거나, 더 복잡한 조건으로 데이터를 조회하고 분석하는 작업이 훨씬 강력하고 유연해집니다. Pandas와도 매우 잘 연동됩니다.
- 숙련도 점검: (자신의 이해도와 문제 해결 능력을 스스로 테스트하는 방법)
- "스트레스 테스트":
- 의도적으로 매우 큰 더미(dummy) JSON 데이터 파일(예: 상품 10만 개, 각 상품마다 복잡한 정보 포함)을 만들어서 스크립트 3으로 처리해보세요. 프로그램이 메모리를 얼마나 사용하는지, 완료까지 얼마나 시간이 걸리는지 측정하고, 예상치 못한 오류는 없는지 확인합니다.
- 스크립트 1, 2 실행 중에 의도적으로 인터넷 연결을 잠시 끊었다가 다시 연결하거나, proxies.txt 파일에 일부러 잘못된 프록시 정보를 넣어보세요. 프로그램이 이런 상황을 어떻게 감지하고, 재시도 로직이 잘 동작하는지, 최종적으로 어떻게 보고하는지 관찰합니다.
- "새로운 요구사항 추가" 시뮬레이션:
- "엑셀 보고서에 '최근 7일 평균 엑세스 수' 컬럼을 추가해주세요." 또는 "특정 카테고리 상품만 따로 집계해서 다른 시트에 보여주세요." 같은 새로운 요구사항이 생겼다고 가정하고, 현재 코드 구조에서 얼마나 빠르고 안정적으로 이 기능을 추가할 수 있을지 직접 구현해보세요. 이 과정에서 코드의 유연성과 확장성을 점검할 수 있습니다.
- 추가 리소스: (이 주제를 더 깊이 파고들고 싶을 때 도움이 될 만한 자료들)
- 초급 (파이썬 기본 및 Pandas 입문):
- 점프 투 파이썬 (책 또는 온라인 위키독스): 파이썬 문법부터 차근차근 배울 수 있는 최고의 입문서.
- 생활코딩 - Python (웹사이트): 쉽고 재미있는 강의로 파이썬 기초를 다질 수 있습니다.
- Pandas 공식 문서 - 10 minutes to pandas: Pandas의 핵심 기능을 빠르게 훑어볼 수 있는 튜토리얼.
- 중급 (Pandas 심화, Asyncio, PyQt5):
- "Python for Data Analysis" (책, Wes McKinney 저): Pandas를 만든 사람이 직접 쓴, Pandas의 바이블과도 같은 책입니다. (번역서: 파이썬 라이브러리를 활용한 데이터 분석)
- 파이썬 공식 문서 - Asyncio: 비동기 프로그래밍의 기본 개념과 사용법을 가장 정확하게 알 수 있습니다.
- "씹어먹는 PyQt5" (온라인 강의/블로그): PyQt5를 실용적인 예제와 함께 배울 수 있는 좋은 자료입니다. (검색 필요)
- Real Python (웹사이트): Pandas, Asyncio, PyQt5 등 다양한 파이썬 주제에 대한 고품질 튜토리얼이 많습니다.
- 고급 (성능 최적화, 클린 코드, 고급 설계):
- "Fluent Python" (책, Luciano Ramalho 저): 파이썬을 파이썬답게 사용하는 방법, 고급 문법과 내부 동작 원리를 깊이 있게 다룹니다. (Asyncio 관련 내용도 훌륭)
- "Clean Code" (책, Robert C. Martin 저): 특정 언어에 국한되지 않고, 읽기 좋고 유지보수하기 좋은 코드를 작성하는 원칙을 배울 수 있습니다.
- 파이썬 프로파일링 도구 (
cProfile,line_profiler등) 사용법 익히기: 코드의 어느 부분이 느린지 병목 지점을 찾아 성능을 개선하는 데 도움이 됩니다.
📝 지식 압축 요약
우리 프로그램이 자꾸 멈췄던 건, 한 번에 너무 많은 데이터를 기억하려 했거나(메모리 부족), 웹에서 정보 가져오다 작은 실패에 쉽게 포기했기(재시도 로직 부재) 때문이었습니다. 이 문제를 해결하기 위해, 데이터를 똑똑하게 다루는 'Pandas'라는 마법 상자를 사용하고, 실패해도 몇 번 더 도전하는 '끈기'를 프로그램에 심어주었습니다. 앞으로 큰 데이터는 잘 나눠서 처리하고(Pandas 생활화), 외부 작업은 항상 예외를 대비하며(견고한 I/O), 조금씩 만들고 자주 테스트하는 습관을 들이면, 훨씬 더 튼튼하고 믿음직한 프로그램을 만들 수 있을 겁니다!
댓글
댓글 로딩 중...