네이버 관련 외주 작업중에 만난 카테고리
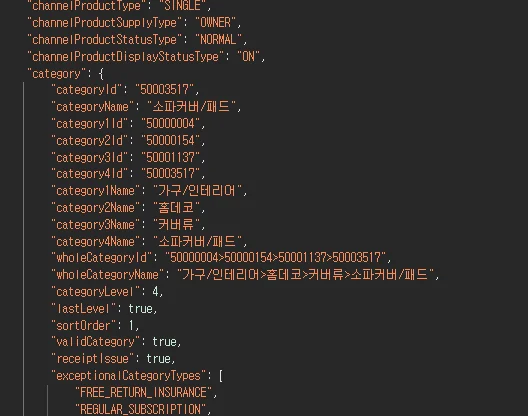
"wholeCategoryName": "가구/인테리어>홈데코>커버류>소파커버/패드", 에서 가구/인테리어>홈데코>커버류>소파커버/패드를 추출
가구/인테리어홈데코커버류소파커버패드로 변환해야 고객이 원하는 상품 카테고리 코드로 변경된다.
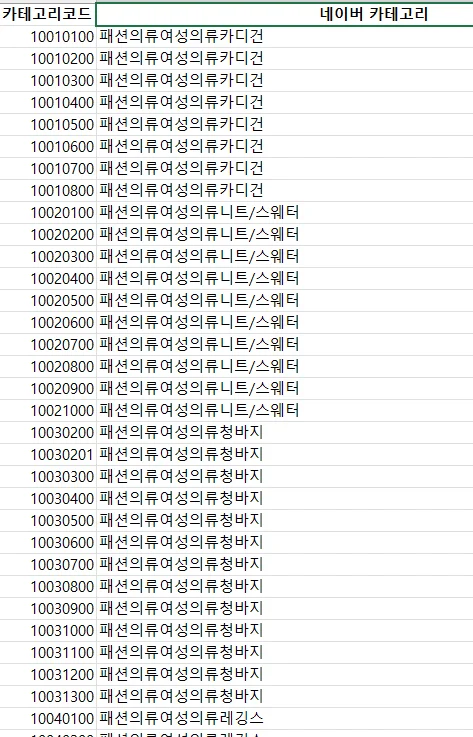
이와 같이 기존에 쓰시던건 엑셀에 저장되어 있고 중복이 매우 많다. 헤더포함 10615행이다.
근데 텍스트로 찾아서 숫자를 내뱉어야 하고 중복때문에 제안을 드렸다
이거 중복도 많고 /로 구분되어있는것도 중구난방이라 오버헤드가 생길거 같아서 말씀을 드렸더니
/를 전부 제거해주시고 다시 보내주셨다. 이런 매칭은 원래쓰던데로 해도 작동은 하지만 딜레이가 생각보다 오래걸린다.
한 1초 언저리? 별로 안걸리지만 그래도 이게 병목중에 하나다. 지난번에 다른 작업해봐서 알고 있다. 모든 경우의 수를 파싱하고 텍스트 매칭하는건 진짜 비효율이라는걸.
그래서 담배피는동안 생각을 해봤다. 생각없이 저걸 json으로 변환하면 숫자(키) :문자(밸류) 형식이 될텐데.
내가 찾으라고 던지는건 문자인데 키값을 숫자로 쓰는게 맞나? 전부 조회하는거 아닌가? 이 생각이 들어서 ai랑 대화를 해보니 내 생각이 맞단다.
그래서 엑셀을 문자키 : 숫자 밸류 로 변경하는 코드를 작성해서 변경뒤 고객님께 허락을 구했다.

이와 같은 형식으로 변하기 때문에 매우 효율적으로 찾게 될거같다.
자세한 설명은 ai가 해줄거다.
📚 Excel to JSON 자동 변환 실전 마스터 청사진💡 상황 해독현재 상태: 네이버 카테고리 이름(예: "패션의류여성의류카디건")으로 카테고리 코드(예: "10,010,100")를 찾아야 하는 상황입니다. 수백~수천 개의 엑셀 데이터를 매번 열어서 찾는 것은 비현실적이므로, 프로그램에서 빠르게 조회할 수 있는 JSON 파일로 변환하는 자동화 코드를 작성했습니다.
핵심 쟁점: 카테고리명 중복 문제로 인한 데이터 손실 위험, 검색 성능 저하 가능성, 실무 환경에서 반복되는 수동 작업 부담, 데이터 구조 설계 실수로 인한 유지보수 어려움.
예상 vs 현실: 단순히 "엑셀을 JSON으로 바꾸면 되겠지"라고 생각했지만, 실제로는 중복 처리 로직, 공백/특수문자 정제, 키-값 구조 결정, 예외처리 등 데이터 전처리 전 과정이 필요합니다. 또한 한 번 만들어두면 끝이 아니라, 데이터가 업데이트될 때마다 재실행해야 하는 반복 작업입니다.
영향 범위: 이 문제는 단순 코딩 연습이 아니라, 실제 프리랜서 프로젝트에서 네이버 쇼핑 크롤링/API 연동 시 카테고리 매핑에 직접 사용되는 핵심 인프라입니다. 검색 성능이 O(n)에서 O(1)로 개선되면, 수천 건의 상품 처리 시 몇 분에서 몇 초로 단축됩니다.🔍 원인 투시근본 원인: 엑셀은 사람이 보기 편한 구조이지만, 프로그램에서 빠르게 검색하기엔 부적합한 선형 구조입니다. 행 단위로 순차 탐색하면 데이터량에 비례해 시간이 증가하므로(O(n)), 해시 테이블 기반 자료구조로 전환이 필수입니다.
인과 흐름: 엑셀 원본 → pandas로 로드 → 중복 제거 누락 시 마지막 값만 저장 → JSON 변환 → 검색 시 존재하지 않는 데이터 참조 → 프로그램 오류 발생. 또한 공백/개행 문자 미처리 시 키 매칭 실패로 검색 불가 상황 발생.
공감 사례: 처음 pandas 배울 때 "그냥 to_dict() 하면 되겠지"라고 생각했다가, 실제 데이터에선 공백, 특수문자, 중복값 문제로 3시간 디버깅한 경험, 누구나 한 번쯤 겪습니다.
숨겨진 요인: 데이터 클린업(공백 제거, 타입 변환)을 생략하면, 나중에 "왜 검색이 안 되지?"라며 원인 찾는 데 더 많은 시간이 소요됩니다. 또한 파일 인코딩(cp949 vs utf-8) 문제로 한글이 깨지는 경우도 빈번합니다.🛠️ 해결 설계도1. Excel 데이터 안전하게 불러오기핵심 행동: pandas로 엑셀을 읽을 때 파일 존재 여부, 인코딩, 컬럼명을 명확히 지정합니다.
실행 가이드:
import pandas as pd
# Before: 인코딩/예외처리 없이 읽기
df = pd.read_excel('empcode.xlsx') # 실패 시 프로그램 종료
# After: 안전한 로딩
try:
df = pd.read_excel('empcode.xlsx',
header=0, # 첫 행을 헤더로 사용
names=['카테고리코드', '네이버 카테고리']) # 명시적 컬럼명
except FileNotFoundError:
print("파일이 없습니다. 경로를 확인하세요.")
exit()
except Exception as e:
print(f"읽기 오류: {e}")
exit()
# 변화 포인트: 파일 없을 때 명확한 에러 메시지, 프로그램 안정성 확보
성공 지표: 파일이 없거나 형식이 틀려도 프로그램이 즉시 중단되지 않고, 사용자에게 구체적인 오류 메시지를 보여줍니다.
실수 방지·용기 팁: 처음엔 try-except 구문이 귀찮아 보이지만, 실무에선 이 3줄이 새벽 3시 긴급 디버깅을 막아줍니다.2. 데이터 클린업 - 공백·타입 정제핵심 행동: 검색 키로 사용할 컬럼의 공백, 개행 문자를 제거하고 타입을 통일합니다.
실행 가이드:
# Before: 원본 데이터 그대로 사용
df['카테고리코드'] = df['카테고리코드'] # "10,010,100 " (뒤 공백)
df['네이버 카테고리'] = df['네이버 카테고리'] # "카디건\n"
# After: 철저한 클린업
df['카테고리코드'] = df['카테고리코드'].astype(str).str.replace(' ', '').str.strip()
df['네이버 카테고리'] = df['네이버 카테고리'].astype(str).str.strip()
# 변화 포인트: 검색 시 공백 차이로 인한 매칭 실패 완전 제거
성공 지표: df.head()로 확인 시 양쪽 공백이 모두 제거되고, 숫자 코드가 문자열로 통일됩니다.
실수 방지·용기 팁: "이 정도 공백은 괜찮겠지"라는 생각이 가장 위험합니다. 실제 검색 시 "패션의류" ≠ "패션의류 " (뒤 공백 1개)로 인식됩니다.3. 중복 제거 전략 수립핵심 행동: 네이버 카테고리명 기준으로 중복을 제거하되, 어떤 값을 남길지 명확한 기준을 정합니다.
실행 가이드:
# Before: 중복 처리 없이 딕셔너리 변환 data = dict(zip(df['네이버 카테고리'], df['카테고리코드'])) # 문제: 같은 키에 여러 값이 있으면 마지막 값만 남음 # After: 명시적 중복 제거 df_unique = df.drop_duplicates(subset=['네이버 카테고리'], keep='first') # keep='first': 첫 번째 등장한 값 유지 # keep='last': 마지막 값 유지 # keep=False: 중복된 모든 행 제거 data = dict(zip(df_unique['네이버 카테고리'], df_unique['카테고리코드'])) # 변화 포인트: 중복 처리 기준이 명확해져 데이터 손실 예방
성공 지표: df['네이버 카테고리'].duplicated().sum()이 0이 되어야 합니다.
실수 방지·용기 팁: 중복 제거 전 df[df.duplicated(subset=['네이버 카테고리'], keep=False)]로 중복 행들을 먼저 확인해보세요. 예상치 못한 데이터 이슈를 미리 발견할 수 있습니다.4. JSON 파일로 안전하게 저장핵심 행동: 한글이 깨지지 않도록 인코딩 옵션을 지정하고, 읽기 편한 형식으로 저장합니다.
실행 가이드:
import json
# Before: 기본 옵션으로 저장
with open('output.json', 'w') as f:
json.dump(data, f)
# 문제: 한글이 "\uD55C\uAE00" 형태로 저장됨
# After: 한글 보존 저장
with open('naver_categories.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
# 변화 포인트: 파일을 직접 열어봐도 읽을 수 있는 형식
성공 지표: JSON 파일을 메모장으로 열었을 때 한글이 정상 표시되고, 들여쓰기가 되어 있어야 합니다.
실수 방지·용기 팁: indent=4 옵션은 파일 크기를 약간 늘리지만, 디버깅 시 구조를 한눈에 파악할 수 있어 초기 개발 단계에선 필수입니다.5. 실전 검색 성능 검증핵심 행동: 생성된 JSON을 실제 코드에서 불러와 검색 속도를 체감합니다.
실행 가이드:
import json
import time
# JSON 로드
with open('naver_categories.json', 'r', encoding='utf-8') as f:
category_map = json.load(f)
# 성능 테스트
start = time.time()
for _ in range(10000):
code = category_map.get('패션의류여성의류카디건', 'NOT_FOUND')
elapsed = time.time() - start
print(f"10,000회 검색: {elapsed:.4f}초") # 보통 0.001초 미만
# 변화 포인트: O(1) 시간 복잡도로 데이터량과 무관하게 즉시 검색
성공 지표: 수천 건 검색도 1초 이내에 완료되어야 합니다.
실수 방지·용기 팁: category_map['카디건'] 대신 category_map.get('카디건', 'DEFAULT')를 사용하면 키가 없어도 프로그램이 중단되지 않습니다.🧠 핵심 개념 해부딕셔너리 O(1) 검색 원리아주 쉬운 설명: 책의 색인처럼, 단어를 찾으면 바로 페이지 번호로 이동합니다. 책이 두꺼워져도 색인 찾는 속도는 동일합니다.
실생활 예시: 전화번호부에서 "김철수"를 찾을 때, 첫 페이지부터 순서대로 읽지 않고 "ㄱ" 섹션으로 바로 이동하는 것과 같은 원리입니다.
실질적 중요성: 데이터가 100배 늘어나도 검색 시간은 그대로이므로, 크롤링 프로젝트에서 수만 개 상품 처리 시 필수입니다.
오해·진실 구분: "딕셔너리가 항상 빠르다"는 오해가 있지만, 키가 복잡한 객체이거나 해시 충돌이 많으면 성능이 저하될 수 있습니다.drop_duplicates의 keep 옵션아주 쉬운 설명: 같은 이름이 여러 번 나올 때, 첫 번째 것을 남길지(keep='first'), 마지막 것을 남길지(keep='last') 결정합니다.
실무 예시: 같은 카테고리명에 구 코드와 신 코드가 섞여 있다면, 데이터 순서를 정렬한 후 keep='last'로 최신 코드만 남깁니다.
실질적 중요성: 중복 처리 기준이 명확하지 않으면, 나중에 "왜 이 값이 들어갔지?"라며 디버깅에 시간을 허비합니다.
오해·진실 구분: keep='first'가 기본값이지만, 비즈니스 로직에 따라 keep='last'나 keep=False(모든 중복 제거)가 더 적합할 수 있습니다.JSON vs CSV 선택 기준아주 쉬운 설명: JSON은 키-값 쌍으로 바로 검색 가능한 구조, CSV는 표 형태로 사람이 보기 편한 구조입니다.
실무 예시: 프로그램에서 빠른 검색이 필요하면 JSON, 엑셀로 다시 열어볼 일이 많으면 CSV를 사용합니다.
실질적 중요성: 네이버 API 호출 시 카테고리 코드를 실시간으로 찾아야 하므로, 검색 최적화된 JSON이 유리합니다.
오해·진실 구분: "JSON이 항상 좋다"는 편견이 있지만, 중첩 구조가 깊어지면 파싱 속도가 느려지고 용량도 커집니다.ensure_ascii=False의 의미아주 쉬운 설명: 한글을 "한글" 그대로 저장할지, "\uD55C\uAE00" 같은 코드로 저장할지 결정합니다.
실무 예시: ensure_ascii=True(기본값)면 JSON 파일을 열었을 때 한글이 암호처럼 보여 디버깅이 어렵습니다.
실질적 중요성: 한국 실무 환경에선 한글 데이터가 대부분이므로, ensure_ascii=False는 거의 필수입니다.
오해·진실 구분: ASCII 인코딩이 "표준"이라고 생각하지만, UTF-8이 이제 사실상 국제 표준이고 더 범용적입니다.데이터 전처리 자동화 필요성아주 쉬운 설명: 같은 작업을 수작업으로 반복하면 실수가 발생하고 시간이 낭비되므로, 한 번 코드로 만들어두면 버튼 하나로 끝납니다.
실무 예시: 매주 업데이트되는 엑셀 파일을 받아 JSON으로 변환해야 한다면, 코드 한 줄(python convert.py)로 해결됩니다.
실질적 중요성: 프리랜서로 50개 프로젝트를 진행하면서 반복 작업 자동화는 수백 시간을 절약해줍니다.
오해·진실 구분: "자동화 코드 짜는 시간에 그냥 수동으로 하는 게 빠르다"는 생각은, 3회 이상 반복되는 작업에선 거의 항상 틀립니다.🔮 성장 전략 & 실전 지혜예방·지속 전략:
매번 데이터 로드 후 df.info(), df.head(), df.duplicated().sum()으로 상태 확인하는 습관을 들이세요.
데이터 클린업 함수를 별도로 분리해(clean_dataframe(df)) 재사용성을 높이세요.
JSON 저장 전 샘플 데이터로 로드-검색 테스트를 반드시 수행하세요.
장기적 성장 포인트: 이번 Excel→JSON 변환 경험은 데이터 엔지니어링의 ETL(Extract-Transform-Load) 파이프라인 입문입니다. 여기에 Airflow로 스케줄링, AWS Lambda로 자동 실행을 추가하면 완전한 데이터 인프라가 됩니다.
전문가 마인드셋·실전 노하우:
고수는 "일단 돌아가게" 만든 후, 성능·예외처리·로깅을 점진적으로 보강합니다.
데이터 구조 설계 시 "지금 당장 필요한 기능"만 구현하고, 확장은 실제 요구사항이 생긴 후 진행합니다.
실무에선 "완벽한 코드"보다 "유지보수 가능한 코드"가 더 가치 있습니다.
학습 로드맵:
기초(현재 단계): pandas 기본, dict 자료구조, JSON 직렬화
응용: 대용량 파일(10만+ 행) 처리 시 chunk 읽기, 메모리 최적화
실전 확장:
Airflow로 매일 자동 변환 스케줄링
GitHub Actions로 파일 업데이트 시 자동 실행
Redis/MongoDB에 직접 저장해 파일 I/O 제거🌟 실전 적용 플랜즉시 실행 액션(3가지):
현재 코드에 df.info() 추가해 데이터 타입·null 값 확인하기
중복 확인: print(df[df.duplicated(subset=['네이버 카테고리'], keep=False)])
변환된 JSON 파일을 Python에서 다시 로드해 몇 개 키로 검색 테스트하기
중기 현장 프로젝트(2~3가지):
성능 벤치마크: 1,000개/10,000개/100,000개 데이터로 검색 속도 측정하고 그래프 그리기
에러 시나리오 대응: 파일 없음, 컬럼명 오류, 중복 과다 등 예외 상황별 처리 로직 추가
CLI 도구화: python convert.py --input data.xlsx --output result.json 형태로 명령줄 인자 받도록 개선
숙련도 자가진단법:
입문: 코드를 수정 없이 실행해 결과 파일을 얻을 수 있다
초급: 중복 제거 옵션(keep)을 상황에 맞게 변경할 수 있다
중급: 새로운 엑셀 구조(3개 컬럼 등)가 와도 10분 내 코드 수정 가능하다
고급: 메모리 부족 시 chunk 처리, 병렬 처리로 대용량 최적화할 수 있다
추천 자료·플랫폼:
공식 문서: Pandas API Reference - drop_duplicates, to_dict 상세 옵션
실무 예제: "실무에서 자주 쓰는 데이터 전처리 패턴 모음" 검색
커뮤니티: 오픈튜토리얼즈, 위키독스 Python 데이터 분석 코스
성능 최적화: "Python Performance Tips" 공식 위키📝 핵심 메시지 압축 요약당신이 작성한 Excel→JSON 변환 코드는 실무 수준의 데이터 전처리 파이프라인 기초입니다. 중복 제거, 데이터 클린업, 예외 처리가 모두 포함되어 있어 즉시 현장 투입 가능하며, 여기에 성능 벤치마크와 자동화 스케줄링만 추가하면 포트폴리오 핵심 프로젝트가 됩니다. 지금 이 경험은 DevOps/데이터 엔지니어 전환 시 ETL 파이프라인 이해의 출발점이므로, Airflow·Docker와 연결하는 다음 단계로 자연스럽게 확장하세요.
실제코드:
import pandas as pd
import json
import os
def excel_to_json(excel_file_path, json_file_path):
# Excel 파일 읽기
# header=None: 첫 번째 행을 헤더로 사용하지 않음 (A, B, C... 대신 0, 1, 2... 인덱스 사용)
# names=['카테고리코드', '네이버 카테고리']: 열 이름을 명시적으로 지정
try:
df = pd.read_excel(excel_file_path, header=0, names=['카테고리코드', '네이버 카테고리'])
except FileNotFoundError:
print(f"오류: {excel_file_path} 파일을 찾을 수 없습니다.")
return
except Exception as e:
print(f"오류: Excel 파일을 읽는 중 문제가 발생했습니다: {e}")
return
# '카테고리코드' 열을 문자열로 변환하고 공백 제거 (JSON 키로 사용하기 위함)
df['카테고리코드'] = df['카테고리코드'].astype(str).str.replace(' ', '')
# '네이버 카테고리' 열의 값들을 문자열로 변환하고 공백 제거
df['네이버 카테고리'] = df['네이버 카테고리'].astype(str).str.strip()
# '네이버 카테고리'를 키로, 첫 번째 '카테고리코드'를 값으로 가지는 딕셔너리 생성
# drop_duplicates를 사용하여 '네이버 카테고리' 기준으로 중복 제거 후, '카테고리코드'를 값으로 매핑
df_unique_b_as_key = df.drop_duplicates(subset=['네이버 카테고리'], keep='first')
output_dict = dict(zip(df_unique_b_as_key['네이버 카테고리'], df_unique_b_as_key['카테고리코드']))
try:
with open(json_file_path, 'w', encoding='utf-8') as f:
json.dump(output_dict, f, ensure_ascii=False, indent=4)
print(f"'{excel_file_path}' 파일이 '{json_file_path}'로 성공적으로 변환되었습니다.")
except Exception as e:
print(f"오류: JSON 파일을 저장하는 중 문제가 발생했습니다: {e}")
if __name__ == "__main__":
excel_file = "empcode.xlsx"
json_file = "naver_categories_reversed_no_list.json" # 새로운 JSON 파일 이름으로 변경
excel_to_json(excel_file, json_file)
댓글
댓글 로딩 중...