

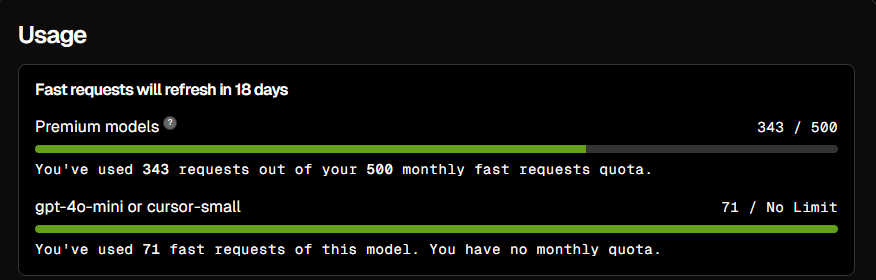
AI 모델을 사용할 때, 특히 GPT 기반 모델이나 자연어 처리(NLP) 모델에서는 "토큰(token)"이 중요한 자원임. 토큰은 모델이 입력 텍스트를 처리하거나 출력 텍스트를 생성할 때 사용하는 기본 단위인데, 이를 효율적으로 관리하지 못하면 리소스 낭비가 발생함. 커서 AI(Cursor AI) 0.46 버전에서도 이러한 토큰 낭비 문제가 제기되고 있음.
이 글에서는 커서 AI의 토큰 낭비 문제가 무엇인지, 왜 발생하는지, 그리고 이를 해결하기 위한 접근법에 대해 살펴볼 예정임.
본론
1. 토큰 낭비 문제의 정의
토큰 낭비란 모델이 불필요하거나 비효율적인 방식으로 토큰을 소비하는 상황을 의미함. 이는 다음과 같은 상황에서 발생할 수 있음:
- 불필요한 반복: 동일한 정보가 여러 번 생성되거나 요청됨.
- 과도한 길이: 간결하게 표현할 수 있는 내용을 지나치게 길게 생성.
- 불필요한 컨텍스트 유지: 대화나 작업에서 필요하지 않은 오래된 컨텍스트를 계속 유지.
2. 커서 AI 0.46에서의 주요 원인
- 모델 최적화 부족: 최신 버전의 GPT 기반 모델들은 종종 특정 작업에 최적화되지 않아 불필요한 계산을 수행함.
- 컨텍스트 윈도우 관리 실패: 커서 AI는 긴 컨텍스트를 처리할 수 있지만, 필요 없는 정보를 계속 유지하면 토큰 낭비가 심해짐.
- 출력 길이 제어 부족: 사용자 요청에 비해 지나치게 긴 응답을 생성하는 경향.
3. 기술적 배경
커서 AI는 GPT 계열의 모델로, 입력과 출력 모두 토큰 단위로 처리됨. 예를 들어:
- "안녕하세요"라는 문장은 약 3개의 토큰으로 분리됨.
- 모델은 각 토큰을 기반으로 다음 토큰을 예측하여 텍스트를 생성함.
문제는 이 과정에서 불필요하게 많은 토큰이 사용되면, API 호출 비용 증가와 응답 시간 지연 같은 부작용이 발생한다는 점임.
사례·예시 및 응용
1. 사례
- 고객 지원 챗봇: 고객 문의에 대한 간단한 답변 대신 장황한 설명을 제공하여 API 호출 비용 증가.
- 코드 생성 도구: 간단히 작성할 수 있는 코드 스니펫 대신 과도하게 길고 불필요한 주석 포함.
2. 응용
- 토큰 최적화 알고리즘 적용: 불필요한 정보를 제거하고 필요한 핵심 정보만 남기는 방식.
- 출력 길이 제한 설정: 예를 들어, 최대 50개의 토큰만 사용하도록 설정.
- 컨텍스트 윈도우 슬라이딩: 오래된 대화 기록은 자동으로 제거하거나 요약.
장단점 및 주의사항
장점
- 비용 절감: API 호출 비용 감소.
- 응답 속도 향상: 불필요한 계산 감소로 빠른 응답 가능.
- 사용자 경험 개선: 간결하고 명확한 답변 제공.
단점
- 정보 손실 가능성: 지나치게 간략화하면 중요한 정보가 누락될 위험.
- 추가 개발 비용: 최적화를 구현하려면 추가적인 개발 리소스 필요.
주의사항
최적화를 적용할 때는 사용자 요구 사항과 균형을 맞춰야 함. 예를 들어, 고객 지원에서는 간결함과 동시에 충분한 정보를 제공해야 함.
결론
커서 AI 0.46의 토큰 낭비 문제는 효율적인 리소스 관리와 사용자 경험 개선을 위해 반드시 해결해야 할 과제임. 이를 위해 출력 길이 제한, 컨텍스트 관리 최적화, 그리고 사용자 맞춤형 설정 등이 필요함.
추가 학습/참고 항목
- OpenAI API 문서 (토큰 관리 관련 가이드)
- Mixture-of-Experts(MoE) 모델에서의 효율성 연구
- GPT 기반 모델 최적화 사례
Token Waste Issues in Cursor AI Version 0.46
Introduction
When using AI models, particularly those based on GPT or NLP frameworks, tokens are a critical resource. Tokens represent the smallest units of text processed by the model, and inefficient token management can lead to wasted computational resources and increased costs. Cursor AI version 0.46 has been reported to suffer from significant token waste issues, impacting its performance and usability.
Main Discussion
1. Definition of Token Waste
Token waste refers to scenarios where an AI model consumes tokens unnecessarily or inefficiently. Common causes include:
- Redundancy: Repeated generation of identical or unnecessary information.
- Excessive Output Length: Responses that are overly verbose compared to the user's request.
- Inefficient Context Management: Retaining irrelevant or outdated context during interactions.
2. Key Issues in Cursor AI 0.46
Cursor AI version 0.46 has been criticized for several inefficiencies related to token usage:
- Agent Mode Inefficiency: The Agent mode often consumes excessive tokens by hallucinating, looping over irrelevant context, or generating overly verbose responses.
- Context Retention Problems: The model struggles to manage long conversation histories effectively, leading to memory bloat and slower performance.
- Uncontrolled Output Length: Responses frequently exceed the necessary length, further increasing token consumption.
3. Technical Background
Cursor AI processes both input and output in tokenized form:
- For example, a phrase like "Hello, world!" might be split into several tokens depending on the tokenizer used.
- The inefficiency arises when the model unnecessarily expands context or generates lengthy outputs without optimization.
These inefficiencies result in higher API costs, slower response times, and reduced user satisfaction.
Examples and Applications
1. Examples of Token Waste
- Customer Support Chatbot: Instead of providing concise answers, the bot generates lengthy explanations that are irrelevant to the query.
- Code Generation Tool: Produces unnecessarily verbose comments or redundant code snippets.
2. Optimization Strategies
To address these issues:
- Implement algorithms to truncate unnecessary information while preserving essential context.
- Set limits on output length (e.g., capping responses at 50 tokens).
- Use "sliding window" techniques to remove outdated conversation context dynamically.
Pros and Cons of Optimization
Pros
- Cost Reduction: Minimizing token usage lowers API expenses.
- Improved Response Speed: Reducing unnecessary computations enhances performance.
- Better User Experience: Concise and relevant responses improve usability.
Cons
- Potential Information Loss: Over-simplification may omit important details.
- Development Overhead: Implementing optimization features requires additional resources.
Conclusion
The token waste problem in Cursor AI version 0.46 highlights the need for better resource management and optimization techniques in AI systems. Strategies such as output length control, efficient context handling, and user-specific configurations can mitigate these issues, improving both cost efficiency and user satisfaction.
댓글
댓글 로딩 중...